Imputation & Genetics
Given the enormous size of the human genome, how can scientists be accurate and efficient when producing DNA test results? And what happens when a person’s DNA sample has partly "illegible" DNA code? Genetic scientists have a method that speeds up the process, and fills in "gaps," while still providing extremely accurate DNA test results.
What Is Imputation?
In the sciences, imputation is the process of using observed values from a dataset to fill in information for missing values in that same dataset. In plain English, it’s like replacing missing letters in a word based on the letters you can already see.
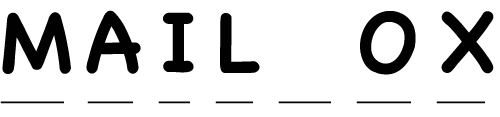
Scientists use the genotype imputation method to fill in missing information when they’re looking at someone’s DNA code. Occasionally, it’s not possible to read the genotype of a specific DNA marker, so imputation is used to infer the identity of a missing marker based on the surrounding DNA.
Scientists often use imputation when they have read a fraction of a person’s genome, but haven’t sequenced all of their DNA. There are tens of millions of sites in your DNA where you can be different from another person, but scientists typically only look at several thousand to a few million when they’re looking for specific sets of markers. Then they use imputation to figure out what the rest of the DNA looks like. In other cases, if there’s been a mistake when they first try to read part of the DNA, they can go back and correct their error using imputation.

How Imputation Works
AncestryDNA® uses imputation when processing your DNA sample to fill out parts of your DNA sequence data we weren’t able to read.
Two main facts about our DNA make imputation possible.
- The hundreds of thousands of markers that scientists look at are lined up, one after the other, across long pieces of DNA called chromosomes.
- People tend to inherit stretches of DNA (rather than individual markers) from their biological parents. Stretches of DNA markers that are frequently inherited together are called haplotypes.
What this means is that when a person inherits a genetic marker for, say, a trait like sweet sensitivity, from one biological parent, they will also get lots of that parent's markers surrounding the specific marker. In other words, a person will inherit a stretch of markers—or haplotype—that includes the sweet sensitivity marker.
It’s like the example pictured above. Say you’re missing a single letter in a word: MAIL_OX. You can probably guess that the missing letter is B, and the word is "mailbox." Imagine that the B is the marker for sweet sensitivity. Even if we don’t see the B in our analysis of your DNA, we can guess what it is from the markers around it.
The marker for those who aren’t sensitive to sweet tastes will have different letters around it. Imagine that it is the T in the word "fortune." So if for some reason we can’t read the sweet sensitivity marker, we can look at the markers around it. If we see MAIL_OX, then we know this person has the sweet sensitivity marker. And if we see FOR_UNE, then we will know the person does not have that marker. In this example, MAILBOX and FORTUNE represent distinct haplotypes.
How DNA Code Helps with Imputation
Of course, DNA doesn’t have English words in it, but it does have a sort of alphabet made up of 4 letters—A (for adenine), C (for cytosine), G (for guanine), and T (for thymine).
For example, say that at the marker for the trait of sweet sensitivity, "yes" to sweet sensitivity is a C and "no" is a T. If we can’t read the letter at that marker, we can impute it from the surrounding markers in the rest of the haplotype.
This real-world example of imputation shows part of the DNA code around the sweet sensitivity marker, giving you an idea of how things work.
DNA code around "yes" to the sweet sensitivity marker, which is in red:

DNA code around "no" to the sweet sensitivity marker, which is in red:

If we couldn’t read the specific marker but saw this, then the sweet sensitivity marker could be inferred or imputed:

How Accurate Is Imputation?
While reliable, imputation has a higher rate of error than simply reading the DNA. Here are several reasons how imputation accuracy can be affected:
- The surrounding markers may be too similar to easily tell apart. This can make it difficult to distinguish the different haplotypes and impute any missing data they contain.
- Haplotypes and their frequencies can vary between populations. This variation can sometimes lead to biases in imputation results.
- If the marker that can’t be read is near the end of a chromosome, then there may not be enough markers on either side of it to act as indicators.
These are just a few of the ways imputation can sometimes be less reliable than directly reading the DNA.






Related articles
Polygenic Risk Score
An AncestryDNA® Traits test can tell you whether you're more or less likely to be an introvert or extrovert, to have the sprinter gene, or if your aversion to cilantro is based in genetics.

Types of DNA Testing
There are multiple types of DNA tests. The three most common are Y-DNA testing, autosomal DNA testing, and mitochondrial DNA testing (mtDNA testing).

Non-Coding DNA
Non-coding DNA is a term in genetics to describe DNA that is not a gene or associated with one. Only about 2% of a person’s DNA is made of base pair sequences for genes.